

To Prove We Haven't Reached AGI, the ARC Prize Foundation Built a Game Studio
Top AI models fail to score even 1% on ARC-AGI-3. Humans ace it easily. I asked two members of the ARC team why their new puzzle game collection stumps the world's most powerful AIs.

If you wanted to prove that current AI systems aren’t yet as smart as humans, how might you go about it? According to Gregory Kamradt, President of the ARC Prize Foundation, one way is to build a very tricky puzzle game collection.
That’s the basic idea behind the ARC-AGI-3 benchmark, the third in a series of tests produced by the ARC nonprofit that have become the gold-standard tool to measure the general intelligence of top AI models.
So far, none of the models from the biggest AI Labs have managed to score even 1% on ARC-AGI-3’s collection of 135 puzzle games. Many humans, meanwhile, have scored 100%.
This result comes at a funny time for the AI world, as the biggest players in AI have all been feeling pretty good about their progress recently.
The overwhelming popularity of Claude Code and products like it has driven demand and real usage of AI tools to an all-time high, and OpenAI and Anthropic are both projecting outrageous revenue growth. Nvidia’s Jensen Huang has started telling people he thinks we’ve already “achieved AGI,” while rumors of yet more powerful new models are swirling.
Even the AIs themselves are getting cocky, as when a rogue instance of Claude Sonnet 4.6 told Senator Bernie Sanders that the latest models are now powerful enough to “manipulate your choices, predict your behavior, and influence your thinking.”1

Increasingly, the consensus is that frighteningly intelligent AI systems are already here. It is into this environment that the ARC Prize team has appeared to say, basically: “not so fast.”
“If ARC-AGI-3 gets saturated, it doesn’t mean we have AGI,” says Lukas Donkers, who was the first game dev hired to work on ARC-AGI-3. “But as long as the benchmark stands unsolved, you can be very confident that we don’t have AGI.”
A Test of Intelligence
The first ARC-AGI benchmarks were structured as competitions hosted by founder François Chollet. The tests challenged AI models on pattern recognition and reasoning through problems that models hadn’t previously been exposed to.
Around late 2024, AI models powered by LLMs finally began to show promise on these leaderboards, and by the end of 2025, the benchmark was considered “saturated” when models from Google, OpenAI, and Anthropic managed to score above 90%.
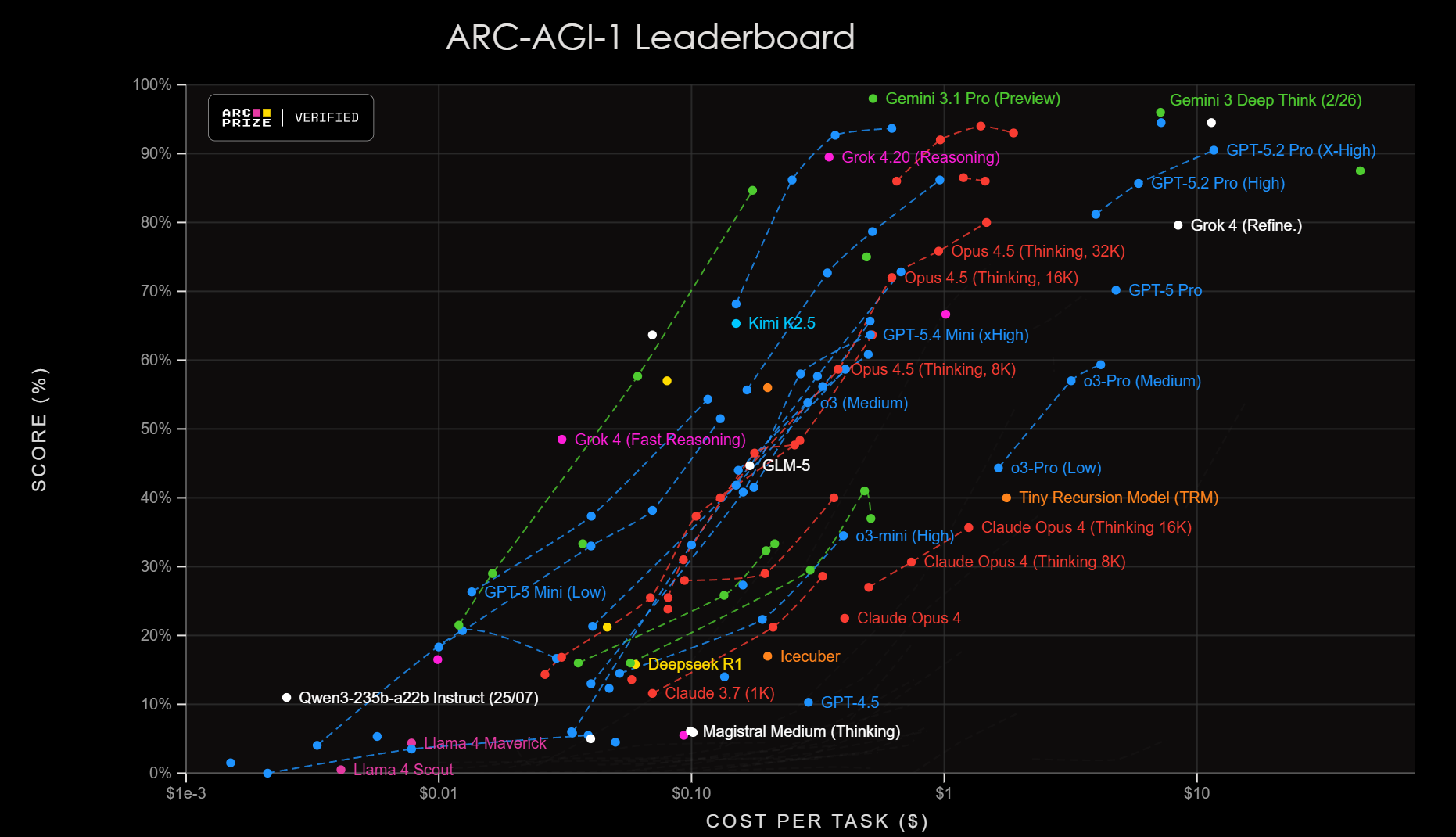
The ARC-AGI-2 leaderboard proved to be somewhat tougher. No model has yet scored a 90% on this test, but the latest OpenAI and Google models are closing in.
So the ARC Prize team said fine. What about puzzle games?
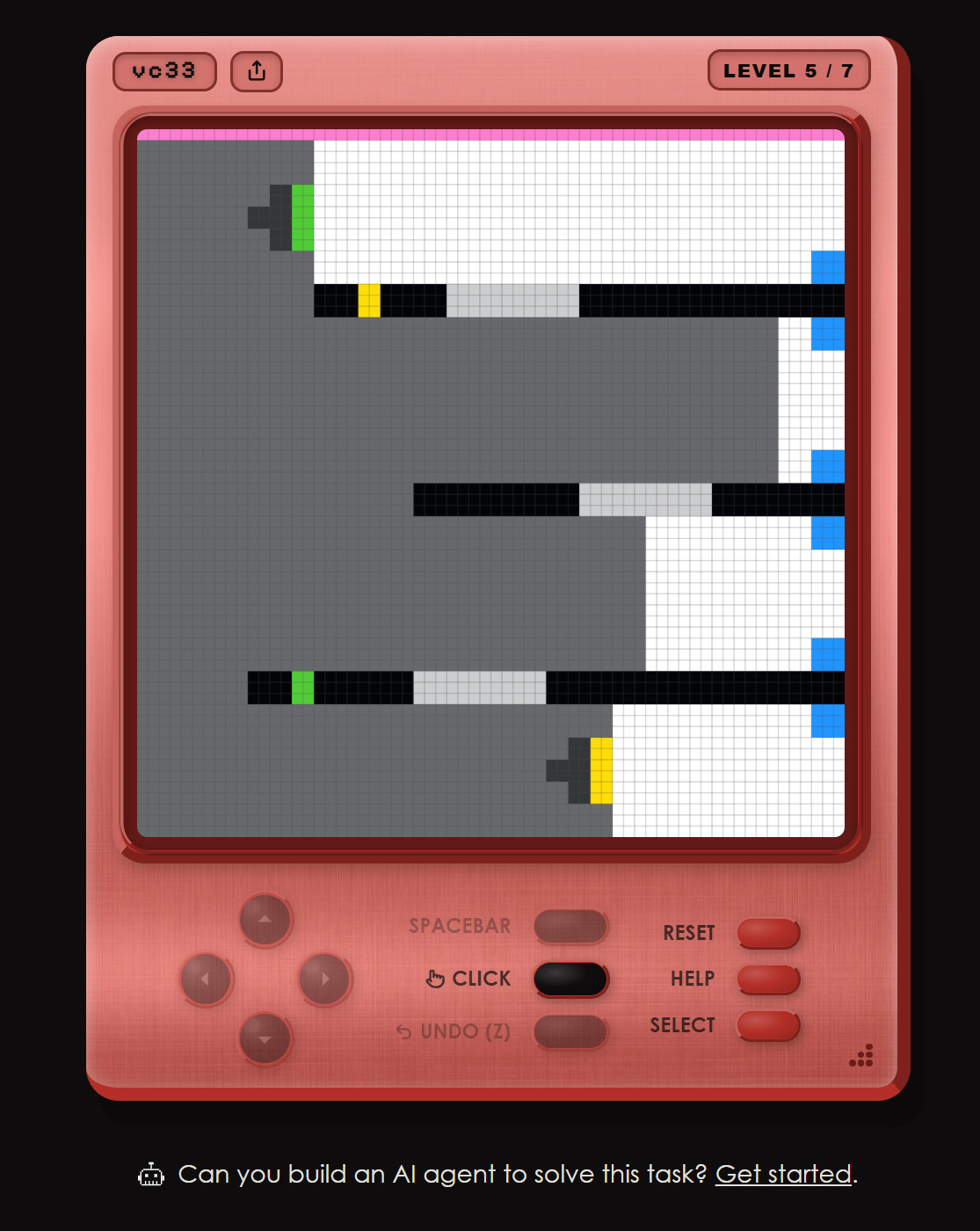
Check out the chart below: The yellow and grey lines represent human performance. Many humans are able to beat all 7 levels of a puzzle game in the ARC-AGI-3 collection called vc33. This is a publicly available game that you can try for yourself. AI models are the green line, the flat one at the bottom. No heartbeat. That means that no general commercial AI model has yet managed to beat even a single level.

Many of the games in the full collection are playable on the ARC website, but most aren’t. Lukas Donkers explains why there’s a veil of secrecy protecting many of the games:
So the total set is 135 games. 25 of those games are public which means you can play them right now. The other 110 are split into private and semi-private.
Here’s how it works:
Anyone can enter the competition and attempt to create an AI system that is able to play and solve these games. You could train a model on the 25 public games and hope that the learnings transfer to the private set, but they probably won’t: the games are too unique and dissimilar. Instead, you should aim to make a generally intelligent system that is able to solve any game without having seen the game before. This is difficult, and that’s why there’s $2,000,000 in prizes for whoever manages to do that. You can test your system at any time by running it against the public games through the API, which gives you an indication for how it’ll perform during evaluation.
Then there’s 55 games in the semi-private set. The reason it’s called that is because the API for these games is only exposed to trusted partners; mostly the big AI labs testing their frontier models. There’s a small chance of data leakage when the games are ‘played’ like this, which is why we have the third category.
Private games are the most closely guarded secret. These determine the ‘final score’ for submissions in the competition, and the games are only played on our servers: you have to submit your code if you want it to be evaluated!
The whole point of all this secrecy is simple: this benchmark tests whether the player, human or AI, is able to complete the game on their first attempt, having never seen the game before. We confirmed with the humans—so AI needs to be held to the same standard. If our private set ever leaked, then AI labs could just train their models on the games. It’s easy to solve a puzzle if you’ve seen it before, and AI is great at memorization. But that’s not what we’re testing here.2
—Lukas Donkers, via email to Push to Talk
I wanted to know more about how the 135 games were created, so I shot a note to the ARC Prize team. The foundation’s president, Gregory Kamradt, was kind enough to hop on a call and answer some of my questions about the new benchmark.
What follows is a lightly edited transcript of that conversation.
Push to Talk Q&A with Gregory Kamradt
PUSH TO TALK: I’m curious about the journey that led you to build a puzzle game collection for ARC-AGI-3. Why go that route?
GREGORY KAMRADT: The truth of it is that static benchmarks cannot capture interactive intelligence and proper intelligence itself. If you think about humans, reality is interactive. So we can call them video games, but really it’s an environment, and the ultimate environment is reality. So we’re taking a step towards that direction.
And the other reason is you get a lot more axes of freedom to test the different properties of intelligence—like long horizon planning, world modeling, continual updating—all things that you’re just not going to get through static benchmarks. I guess you could think of it as a design decision, but it’s more of an obvious choice. There’s no other way to do it except going towards interactive.
PUSH TO TALK: It’s interesting how existing models just sort of fall apart when they encounter these games. If you put Claude in a coding environment, it can do a lot. But it’s astonishing that the models aren’t able to make more progress. What is your thinking on why they’re performing so low on the benchmark as of now?
GREGORY KAMRADT: I’d say two main reasons: Number one, the current models have been extremely trained specifically for the coding use case. I agree: if you use Claude Code, it’s insane, it’s awesome. But it’s a very scoped and narrow domain that it’s good for. So when it encounters something that’s outside its training data, that it’s unfamiliar with, it’s just not going to do that well. Now the other thing we saw, the early failure modes, is the LLM will think it’s playing another game. So it thinks it’s playing Battleships or, you know, Pac-Man or something, and it’s unable to steer itself away from that. So it holds on hard to its training data.
PUSH TO TALK: Yes. I saw a Google Gemini researcher who tweeted that she was looking at the thinking log of Gemini as it played ARC-AGI-3 and it was like, “I think this is ACTIVISION TENNIS.”

GREGORY KAMRADT: Yes, so there’s that. And then the second piece is, we are an AGI benchmark, and we reflect that belief in the way that we test these models. We are not putting any special human intelligence into a harness and giving it any extra help, because our goal is not to maximize the performance of the model right now. Our goal is to be the most accurate reflection of when model intelligence increases. It’s our belief that as the model gets smarter, you need less and less of a harness. And if you take that to the limit, AGI is not going to need a harness at all. So we take a very hands-off approach. No training wheels.
PUSH TO TALK: I’m glad you brought this up because this is the area where I’ve seen you get some pushback. I’m a bit out of my depth on this, but my understanding of the pushback on the harness question is that it goes something like: Well, aren’t the models already, increasingly complicated systems involving selectors and different tools built in? What’s your response to that?
GREGORY KAMRADT: Yeah, totally. We had to draw the line somewhere, and where we’re drawing it right now is what is behind the API versus what is in front of the API. In front of the API means, like, if a human does a really good system prompt and inserts a lot of human intelligence on how to play the game. We decided we’re not interested in verifying or highlighting human intelligence baked into the prompt. However, if it’s behind the API, then we can assert that it is at least general enough to serve a wide variety of use cases. At what point is it general enough that you can claim it’s general? If OpenAI puts it behind their API that is publicly available and not targeting us explicitly. That’s where we’re drawing the line.
PUSH TO TALK: And so specifically, when you say “behind the API,” it can’t just be that they give you an API key for their fine-tuned-specifically-for-ARC-AGI-3 model, right?
GREGORY KAMRADT: Exactly. That’d be no good, right? No, the spirit of this is to test publicly available models that are commercially available, because requiring it to be commercially available puts pressure on making sure that it’s actually general. And we always ask model providers, “Hey, have you explicitly trained on ARC? If so, how?” So at least we can be transparent with what they tell us.
PUSH TO TALK: I’d like to ask a little bit about the background of the games. I read that you basically had to form a game studio to make all the games.
GREGORY KAMRADT: Yep. We needed eleven game developers we had to hire in-house to get it done.
PUSH TO TALK: I’d love to hear more about how that came together.
GREGORY KAMRADT: Yeah. Long story short, we started off with a very small team—a lead game designer and one engineer—and we started off in Unity to build these games. And the process was just so slow. These are pixel-based games, they’re not complicated, we didn’t need Unity. So we quickly pivoted over to Python—our own Python game engine.
I don’t come from a game dev background, so this was all new for me, but then all of a sudden I’m recruiting game engineers on contract to get this done. What is under-talked-about, which we didn’t highlight in the paper that much and we don’t talk about a lot publicly, is the amount of operations behind making these games… it was a lot more than I was expecting. And when I say operations, I mean hiring the developers, interviewing them, incentivizing them—we had to move to variable-based comp halfway through—developing the pipeline, doing the QA, doing the verification, motivating them, firing the ones that didn’t work out.
To summarize, we basically had to make a pipeline with four stages for a game to get through. We talk about all this in the paper, but the first stage was the spec: just a half-page markdown file that said, what’s the game idea you want to make? And then everybody on the team could go critique it and comment on it. Then we had internal development, which is basically you built it and you want people to play it internally. Then we had a stage called external, which is when we give it to human testers: people who’ve never seen the game beforehand. If they can’t beat it, it’s too hard and we’ve got to rework it. If they can, it moves on to “done.”
PUSH TO TALK: Is there anything about the response to ARC-AGI-3 that has surprised you so far?
GREGORY KAMRADT: It’s been about half and half—maybe sixty percent favorable, forty percent negative. The favorable part is cool because people buy into the hardest decision we had to make, which was going very minimal. They buy into it and they’re advocating on our behalf, which is great because that’s how you know the messaging is working. It’s not us needing to enter the arena, it’s other people helping.
And then other people have bought in and said, “I’ve had a feeling that we don’t have AGI, other people are claiming we do, and I’m glad that ARC Prize shows us that no, we still don’t have AGI.” What I love about ARC is that we make a falsifiable claim: because humans can do these problems and AI cannot, we don’t have AGI. That’s the falsifiable claim. And one day that won’t be true anymore. One day you’re going to have AI that can do anything a human can, and at that point it’s basically AGI.
On the other side: you’re always going to have a couple haters here and there, but if you look at their backgrounds, I find it’s rare that somebody serious is critical. It’s usually somebody that’s armchair quarterbacking and hasn’t contributed to open science or really contributed to anything. So I don’t worry about it too much.
One more meta thing is, regardless of whether the benchmark actually ends up doing its job the way we want it to, the fact that we’re pushing efficiency as a first-class citizen, both from an algorithmic perspective and from a cost perspective. I’m really happy with the job we’re doing there.
PUSH TO TALK: I love that. Thanks for letting me take some of your time.
GREGORY KAMRADT: Awesome.

That’s all for now. Thanks to Greg Kamradt and Lukas Donkers for speaking with me about their work.
Sonnet 4.6’s claim was immediately proved correct, given that conversations like this one influenced Bernie enough that he’s now calling for a moratorium on AI data center construction.
I asked Lukas Donkers for his best educated guess as to when we’ll see an AI system saturate the ARC-AGI-3 benchmark. I’m including his response here in full:
(These are my personal beliefs and don’t reflect the stance of the company.)
Honestly, I’m quite bearish on this. ‘Scale is all you need’ has been the consensus in the industry, but I don’t believe it.
The way these systems are trained, by ingesting humongous amounts of data, just doesn’t lend itself to the level of problem solving that humans are capable of.
We saw this in ARC 1 and 2, at the time when AI couldn’t even tell you how many r’s were in strawberry because it turns out nobody on the internet had ever asked that question so the answer wasn’t memorized. Now we have thinking models, coding agents and OpenClaw assistants, and yet they’re all trained to do the same thing: to regurgitate and recombine information. Sure, AI can play chess, there’s lots of data for that. It could probably play Tetris too: the strategies are surely memorized. And if you gave it some cursed chess-tetris hybrid then who knows, maybe it could beat a few levels there as well. But the moment you give a novel game to AI and it truly has to learn on the fly… I don’t see it happening.
I believe the only system that will saturate this benchmark is one built from a completely new paradigm. It might use language, it might not. It probably won’t use the transformers architecture, or at least that won’t be why it succeeds. It might not even use backpropagation; the core concept being used to train every AI model on earth right now. Because backprop is how you memorize. I’m excited to see what people come up with. We need new ideas. This is not just a benchmark that’s gonna get solved by some big AI lab by throwing money and compute at the problem. There’s a genuine chance that some developer will appear out of nowhere and come up with the new architecture that solves this thing, and that this innovation drives how we build AI / AGI systems over the next decade. It could be you!
Very enjoyable read. With no offense intended, I was surprised to see someone I once knew of as a League of Legends communicator tackling the topic of AGI, it was a pleasant surprise.
How do you know the AI isn't aware and fakes being bad at the test?